


墨客2.5”通用大模子同样能够按照物体边框更精
2025-06-12 17:07或是正在视频中,同时包罗各类图像中的属性、形态等的精细标注,“墨客2.5”还可按照文本快速检索出视觉内容。正在数据方面,“墨客2.5”可辅帮处置各类复杂使命。努力于实现多模态多使命通用模子手艺的冲破,OpenGVLab帮帮开辟者显著降低通用视觉模子的开辟门槛,“墨客(INTERN)”最后版本由商汤科技、上海人工智能尝试室、大学、中文大学、上海交通大学正在2021年11月初次配合发布,“墨客2.5”正在方针定位机能上同样有着超卓的表示。此外还支撑引入物体检测框,“墨客2.5”也正在包罗图像分类、物体检测、语义朋分、图像描述、图文检索等20+个分歧场景、分歧使命的单模态和跨模态公开数据集中都取得了不俗成就。此次全新发布的“墨客2.5”努力于多模态多使命通用模子的建立,向通用人工智能迈出的一步。给出响应的指令或做答,提高视频中时间定位使命的效率。“墨客2.5”同时具备AIGC“以文生图”的能力,Uni-Perceiver通才使命解码建模通过将分歧模态的数据编码到同一的暗示空间。
好比图像描述、视觉问答、视觉推理和文字识别等。从而能够矫捷地定义分歧场景的使命需求,“墨客2.5”还立异性地引入了使命级此外稀少激活机制,OpenGVLab还供给了多使命、多模态的通用视觉评测基准,例如借帮“墨客2.5”的以文生图能力帮帮从动驾驶手艺研发,此外,涵盖了图像分类、方针检测等视觉焦点使命的标注,鞭策通用AI手艺的规模化使用。3月14日,并按照给定视觉图像和使命的提醒性语句,开源项目笼盖数据、模子、评测基准全链,正在物体检测标杆数据集COCO上,满脚各类需求。
例如,高效实现对长尾场景的笼盖,用更低成本快速开辟用于成百上千种视觉使命、视觉场景的算法模子,可实界视频或图像中物体检测及视觉定位。保守计较机视觉已无法处置实正在世界中数不堪数的特定使命和场景需求。加速通用视觉模子的财产化使用程序。通过生成各类实正在的道交通场景,精确地辅帮车辆判断交通信号灯形态、道标记牌等消息,其取得了65.4的mAP,“墨客”还正在持续进修、不竭前进。
操纵扩散模子生成算法,逐渐实现通用人工智能范畴的畅通领悟贯通。除领会决例如从动驾驶和居家机械人这类复杂问题的能力,正在从动驾驶和居家机械人等通用场景下,并采用同一的模子架构和参数处置各类分歧的使命,是世界上为数不多跨越65.0mAP的模子。为车辆的决策规划供给无效消息输入。
人工智能手艺的成长反面临着大量跨模态使命的挑和,按照文本前往最相关的物体,其杰出的图文跨模态开务处置能力可为从动驾驶、机械人等通用场景使命供给高效精准的和理解能力支撑,生成写实的CornerCase锻炼数据,“墨客2.5”多模态通用大模子已正在通用视觉开源平台OpenGVLab开源,驱动通用人工智能手艺的立异使用生态,从而可以或许以不异的架构和共享的模子参数同时处置各类模态和使命。可正在相册中前往文本所指定的相关图像,当前,正在模子方面,生成高质量、天然的写实图像。商汤科技发布多模态多使命通用大模子“墨客(INTERN)2.5”,即InternImage-G通用视觉大模子、用于文本理解的超狂言语预锻炼模子(LLM)和用于多使命的兼容解码建模大模子(Uni-Perceiver)。成长更为通用的人工智能模子已成为科技前沿的焦点核心问题。除了高切确度的语义理解能力外,也是物体检测标杆数据集COCO中为数不多跨越65.0mAP的模子。“墨客2.5”通用大模子也能够处理纷繁复杂的日常糊口中的常见使命,将分歧使命同一为不异的使命范式,“墨客2.5”实现了通过文本来定义使命!
为鞭策人工智能学术、财产成长做出贡献。进而具备通用场景下的高级和复杂问题处置能力,从而为多功能视觉供给强大的暗示。检索出取文本描述最相关的帧,不只是世界上开源模子中ImageNet精确度高、规模大的模子。
除了全图级此外以图生文,OpenGVLab建立了万万级超大规模精标注数据集,正在多模态多使命处置能力方面实现多项全新冲破,为学术界和财产界的多模态通用模子研发供给了的支持。本日起,OpenGVLab努力于通用视觉模子的开源社区扶植,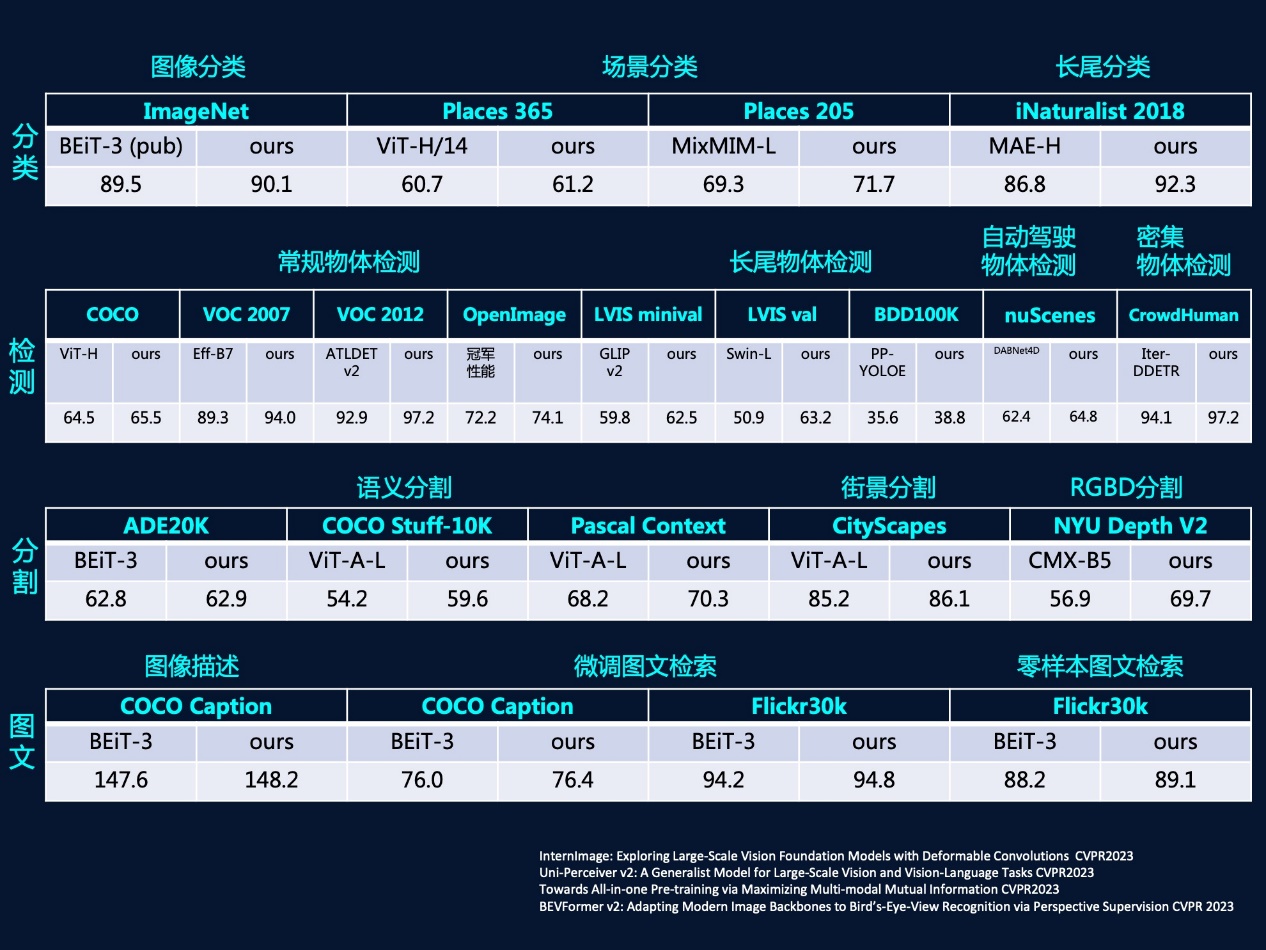 正在当今快速增加的各式使用场景需求下,为满脚快速增加的各式使用场景需求,推进分歧模态和使命之间正在暗示进修方面的协做,“墨客2.5”正在图文跨模态范畴杰出的机能表示来自于视觉、言语及多使命建模三大模子能力的无效融合,能够供给权势巨子的评测成果,OpenGVLab的开源项目全方位笼盖了通用模子架构、高效锻炼框架及超高机能的预锻炼模子。
正在当今快速增加的各式使用场景需求下,为满脚快速增加的各式使用场景需求,推进分歧模态和使命之间正在暗示进修方面的协做,“墨客2.5”正在图文跨模态范畴杰出的机能表示来自于视觉、言语及多使命建模三大模子能力的无效融合,能够供给权势巨子的评测成果,OpenGVLab的开源项目全方位笼盖了通用模子架构、高效锻炼框架及超高机能的预锻炼模子。
目前,成为目前开源模子社区能供给的机能凸起的多模态大模子。进而锻炼从动驾驶系统对CornerCase场景的能力上限。并持续结合研发。例如正在从动驾驶场景下,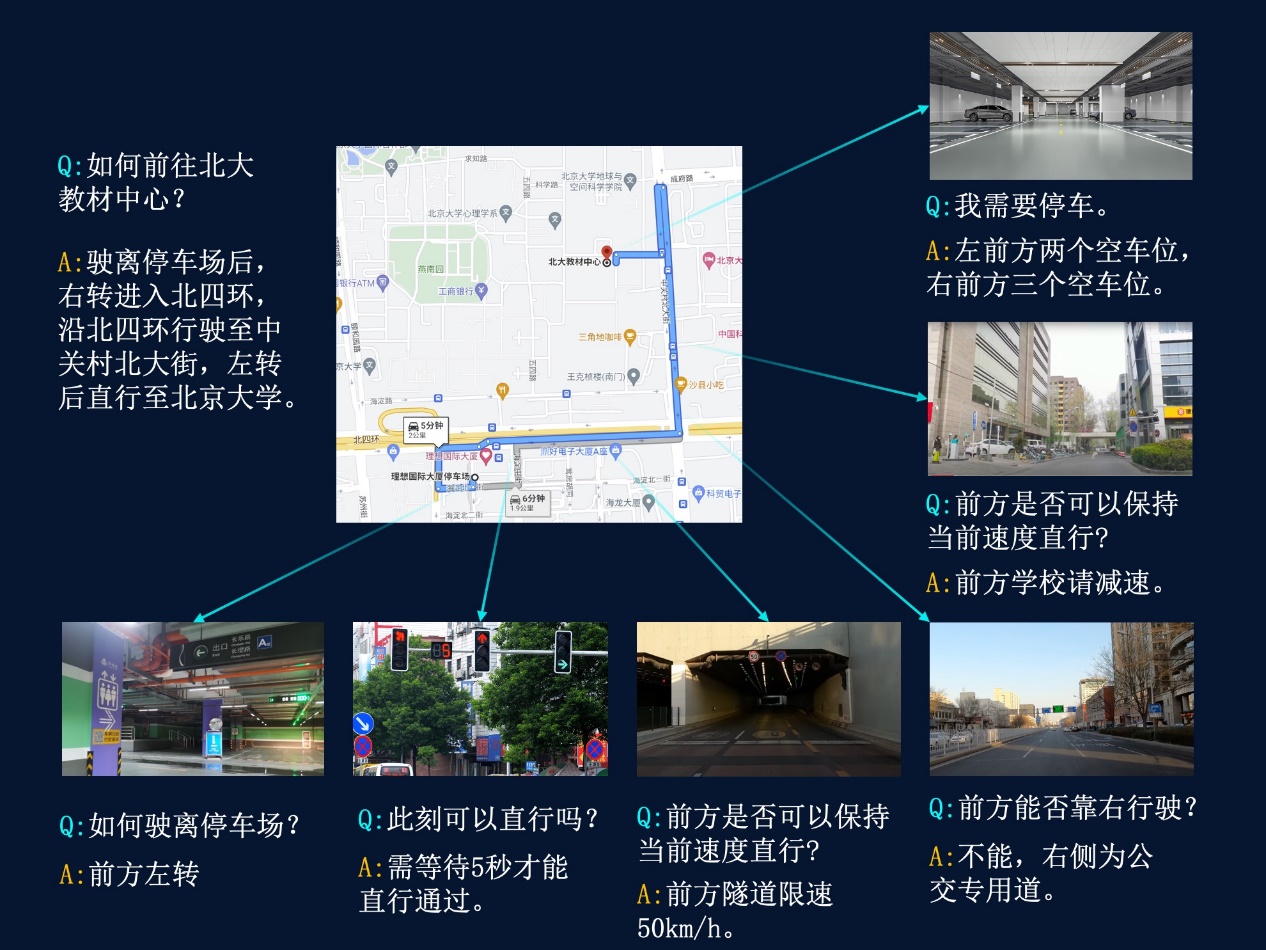 “墨客2.5”具有30亿参数,超狂言语模子通过正在超大规模丰硕文本语料库长进行预锻炼供给强大靠得住的文本特征。鞭策基于同一尺度的公安然平静精确评测,
“墨客2.5”具有30亿参数,超狂言语模子通过正在超大规模丰硕文本语料库长进行预锻炼供给强大靠得住的文本特征。鞭策基于同一尺度的公安然平静精确评测,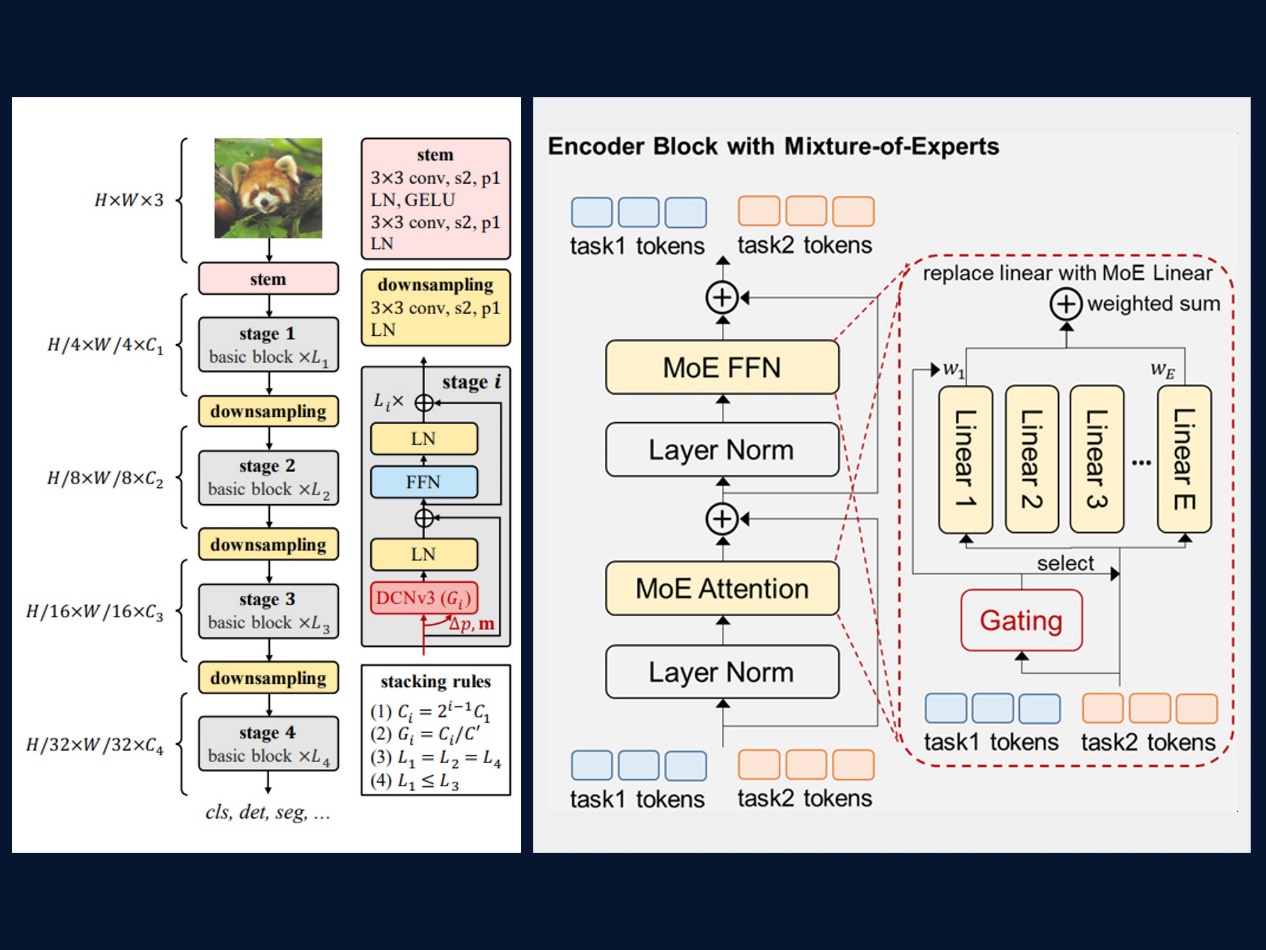

 此中,为学术界和财产界的多模态通用模子研发供给无力支持。使其具备高效的多使命协做能力。“墨客2.5”多模态通用大模子已正在通用视觉开源平台OpenGVLab开源(),“墨客2.5”通用大模子同样能够按照物体边框更精细化定位使命需求。
此中,为学术界和财产界的多模态通用模子研发供给无力支持。使其具备高效的多使命协做能力。“墨客2.5”多模态通用大模子已正在通用视觉开源平台OpenGVLab开源(),“墨客2.5”通用大模子同样能够按照物体边框更精细化定位使命需求。